一、overview
perf是一个性能分析工具,用于在Linux系统上测量和分析程序的性能。它提供了丰富的功能,允许开发人员深入了解应用程序的性能瓶颈和优化机会。
perf工具的核心功能包括:
事件采集:
perf可以利用处理器性能计数器(PMC)来收集各种硬件事件,例如指令执行、缓存命中/不命中、分支预测等。这些事件提供了有关程序在硬件级别上运行时的详细信息。采样分析: 除了事件计数,
perf还可以进行采样分析。它通过定期采样正在运行的程序的指令指针(instruction pointer)来收集信息。这样做的好处是可以避免事件计数可能带来的开销,同时可以捕获更全面的数据,特别是对于长时间运行的应用程序。性能报告:
perf可以生成性能报告,其中包含各种性能指标,例如CPU使用率、指令执行、缓存命中率等。这些报告可帮助开发人员了解程序在运行过程中的性能表现。火焰图: 火焰图是一种用于可视化采样数据的图表。
perf可以生成火焰图,通过展示函数调用层次和占用CPU时间的比例,帮助开发人员更直观地理解程序的热点。跟踪:
perf还支持对程序进行跟踪,以捕获函数调用、系统调用、硬件事件等的信息。这有助于分析程序的执行路径和性能瓶颈。调试符号支持: 为了更好地分析性能数据,
perf支持使用符号表来转换内存地址为函数名和源代码行号。
二、原理
perf的实现原理涉及到Linux内核的perf_events子系统、处理器的性能监测单元(Performance Monitoring Unit,PMU)以及用户空间的perf工具三个主要部分。下面将详细介绍每个部分的作用和原理:
1. perf_events 子系统:
perf工具建立在Linux内核的perf_events子系统之上。该子系统允许用户访问处理器的性能监测单元(PMU),这些监测单元用于测量和记录各种硬件性能事件,例如指令执行、缓存命中、缓存不命中、分支预测等。
perf_events子系统提供了一组系统调用接口,使得用户空间程序可以与内核交互,以配置和启动性能计数器的采样或计数功能,并获取性能数据。这样,perf工具可以通过简单的命令行操作与内核交互,不需要内核模块或驱动的支持,降低了性能分析的开销。
2. PMU(Performance Monitoring Unit):
PMU 是位于计算机处理器内部的特殊硬件单元,用于测量和记录处理器的性能相关事件。它包含一组硬件性能计数器,这些计数器可以用来计算和存储特定事件的数量。
perf工具利用了处理器的PMU来实现性能数据的采集。用户可以通过perf_events子系统配置和启动性能计数器,选择要测量的性能事件,例如指令执行、缓存命中、缓存不命中等。然后,PMU会在应用程序的执行过程中,对指定事件进行计数,或者以一定的频率进行采样。
3. perf工具:
perf工具是位于用户空间的性能分析工具,它与Linux内核的perf_events子系统进行交互,实现性能数据的收集和分析。
用户可以通过perf命令行工具来配置和启动性能计数器,选择要测量的事件,并指定要监测的进程或线程。例如,使用perf stat命令来统计指定进程的性能指标,使用perf record命令来记录性能数据,使用perf report命令来分析和显示性能报告等。
perf工具还支持火焰图(FlameGraph)功能,通过采样分析获取程序的执行堆栈信息,然后利用FlameGraph脚本生成火焰图,直观地展示程序的热点函数和调用路径。
总结起来,perf工具实现的原理是基于Linux内核的perf_events子系统和处理器的PMU功能。它通过配置和启动性能计数器,采集和分析系统和应用程序的性能数据,为开发人员提供了一个强大的性能分析工具。
三、功能使用
基本功能
perf stat 概览程序的运行情况
root@:~# perf stat -p 11491
Performance counter stats for process id '11491':
12361.88 msec task-clock # 0.772 CPUs utilized
49470 context-switches # 0.004 M/sec
110 cpu-migrations # 0.009 K/sec
0 page-faults # 0.000 K/sec
14396484879 cycles # 1.165 GHz
9312889874 instructions # 0.65 insn per cycle
1186201120 branches # 95.956 M/sec
170881927 branch-misses # 14.41% of all branches
16.017543644 seconds time elapsed
root@:~# task-clock: 12361.88毫秒
这是进程运行的总时间,以毫秒为单位。在这个例子中,进程运行了约12361.88毫秒。
CPUs utilized: 0.772
表示进程平均使用了多少个CPU核心。在这个例子中,平均使用了0.772个CPU核心。
context-switches: 49470
表示进程的上下文切换次数。上下文切换是操作系统在不同进程之间切换执行权的操作。在这个例子中,进程的上下文切换次数为49470次。
cpu-migrations: 110
表示进程在不同CPU核心之间迁移的次数。在多核系统上,进程可能会在不同核心之间迁移,以平衡负载。在这个例子中,进程的CPU迁移次数为110次。
page-faults: 0
表示进程的页错误次数。页错误是由于访问未映射到进程虚拟地址空间的内存而导致的。在这个例子中,进程的页错误次数为0次,即没有发生页错误。
cycles: 14396484879
表示进程执行的CPU周期数。在这个例子中,进程执行了约14396484879个CPU周期。
instructions: 9312889874
表示进程执行的指令数。在这个例子中,进程执行了约9312889874条指令。
branches: 1186201120
表示进程执行的分支指令数。在这个例子中,进程执行了约1186201120条分支指令。
branch-misses: 170881927
表示分支预测失败的次数。分支预测是CPU为了加速执行而对分支指令进行的预测。分支预测失败意味着预测出现错误,需要重新执行。在这个例子中,分支预测失败的次数为170881927次,占所有分支的14.41%。
time elapsed: 16.017543644秒
表示从
perf命令开始执行到收集性能数据结束的总时间。在这个例子中,从开始执行perf命令到收集数据结束的总时间为约16.02秒。
perf top -g
用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
[.] : user level 用户态空间,若自己监控的进程为用户态进程,那么这些即主要为用户态的cpu-clock占用的数值
[k]: kernel level 内核态空间
[g]: guest kernel level (virtualization) 客户内核级别
[u]: guest os user space 操作系统用户空间
[H]: hypervisor 管理程序火焰图
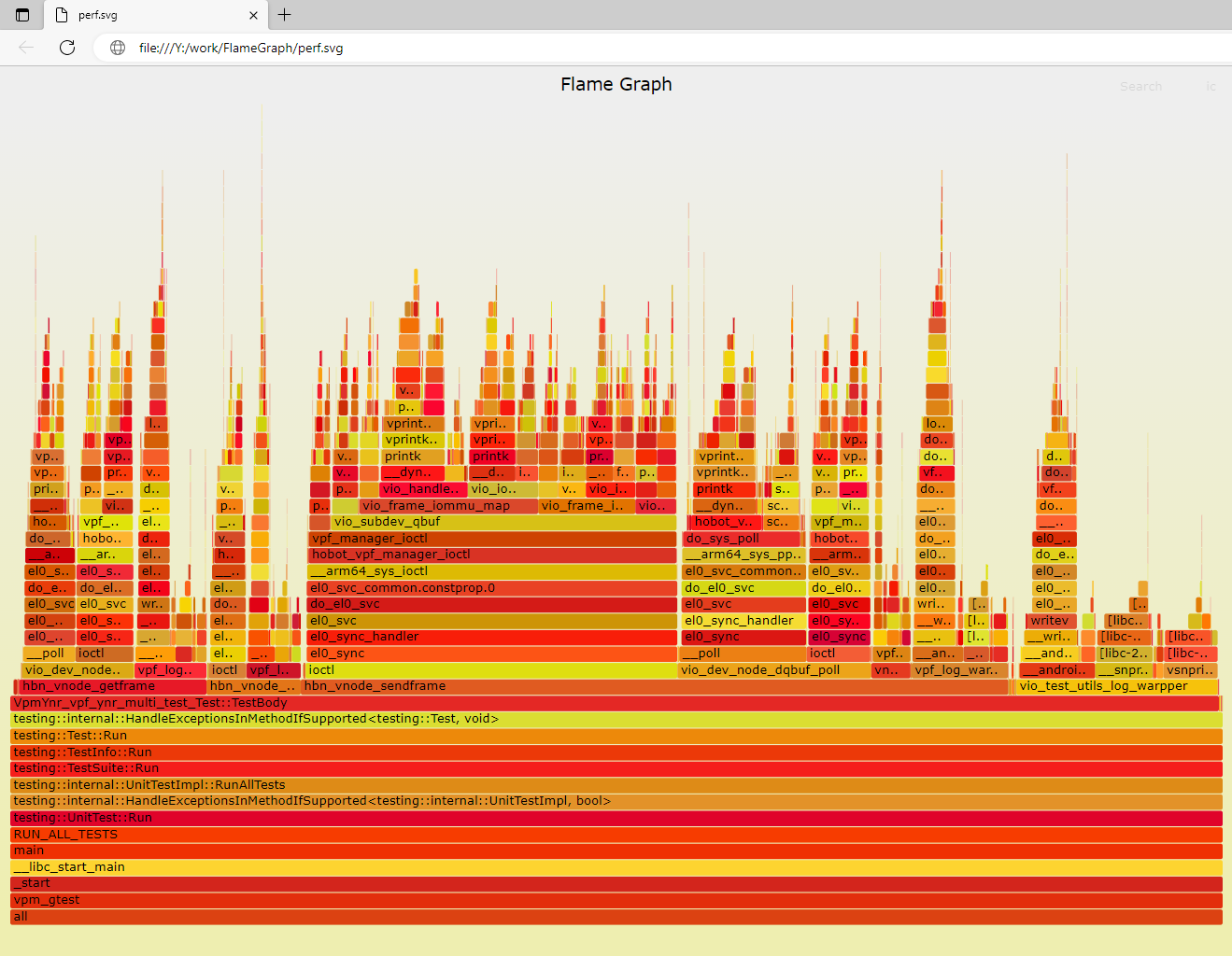
火焰图(Flame Graph)是一种用于可视化性能采样数据的图表,它是由 Brendan Gregg 在2011年首次引入的。火焰图通过堆叠图的方式展示函数调用层次和占用 CPU 时间的比例,使得开发人员可以更直观地了解程序的热点和性能分布。
火焰图的特点和用途:
直观: 火焰图是一种直观的图表,以堆叠矩形的方式表示函数调用层次,上方的函数调用覆盖下方函数的调用。这样可以直观地展示程序在不同函数之间的调用关系和时间占比。
热点可视化: 火焰图可以帮助开发人员快速识别程序的热点,即占用大部分 CPU 时间的函数。这些热点往往是导致性能问题的主要原因。
分层信息: 火焰图提供了函数调用的分层信息,每个矩形代表一个函数,矩形的宽度表示函数在采样数据中的时间占比。
多维度支持: 火焰图可以支持多维度的性能数据,例如 CPU 周期、指令数、内存消耗等。不仅可以用于分析 CPU 性能,还可以用于其他系统资源的分析。
第一步确认pid:
root@j5dvb:/userdata/zzl# ps
PID USER PRI NI VSZ STAT COMMAND
1 root 19 0 5368 S /init --second-stage
2 root 19 0 0 SW [kthreadd]
3 root 39 -20 0 IW< [rcu_gp]
11491 root 19 0 42060 R /user/data/test第二步数据采样:
root@:/userdata/zzl# perf record -p 11491 -F 99 -a -g -- sleep 600
| | | | |
进程pid 采样频率 采用CPU 记录堆栈调用关系 采样时间/s
root@:/userdata/zzl# ls
perf.data第三步解析采用数据:
root@:/userdata/zzl# perf script -i ./perf.data > perf.unfold
root@:/userdata/zzl# ls
perf.data perf.unfold第四步FlameGraph生成火焰图:
stackcollapse-perf.pl :stackcollapse-perf.pl工具解析perf.unfold文件的堆栈调用信息,生成flame.folded中间文件,文件比较大;
flamegraph.pl :flamegraph.pl 工具将stackcollapse-perf.pl生成的带堆栈调用信息的中间文件flame.folded可视化为perf.svg火焰图
zhilu.zhang@ububuntu-server:~/work/FlameGraph$ ./FlameGraph/stackcollapse-perf.pl perf.unfold | ./FlameGraph/flamegraph.pl > perf.svg